
Desbloqueando os segredos do jogo de AlphaZero: como ele aprendeu a vencer Stockfish
ma saudação cordial, caro leitor, antes de começar a leitura deste artigo, recomendo que você prepare um café com alguns bons croissants para aproveitar o que vai ler a seguir

Foto: Stan Honda / AFP / Getty Images
Em 1997, o mundo do xadrez foi abalado pela derrota sofrida por um dos maiores campeões de xadrez de todos os tempos: “Gary Kasparov“, que perdeu para o Deep Blue: um supercomputador que calculava 200 milhões de lances por segundo.
Hoje, o mundo do xadrez foi novamente abalado pelas notícias recentes sobre o Alpha Zero, um programa de IA que esmagou o atual campeão mundial de motores de xadrez.
Mas essa mudança terá mais eco do que a primeira, já que desta vez o programa que atrai atenção é um programa de inteligência artificial que aprendeu a brincar sozinho, sem intervenção humana.
Mas vamos começar do começo. Esses programas começaram a ganhar destaque há alguns anos com o jogo GO.
Go é um jogo inventado na China há mais de 2500 anos, cujo nível de complexidade muitos dizem ser maior do que o do xadrez
AlphaGo foi um programa de computador desenvolvido pela DeepMind, uma empresa dedicada à pesquisa e desenvolvimento de IA, adquirida pelo Google em 2014; esse Programa Alpha Go derrotou dois campeões mundiais de Go

Agora, a AlphaZero venceu a StockFish, a atual campeã mundial de computadores de xadrez
A AlphaZero adotou uma abordagem “mais humana” para a busca de movimentos, processando cerca de 80.000 posições por segundo no xadrez, comparado aos 70 milhões do Stockfish 8.
AlphaZero também aprendeu shogi em duas horas antes de derrotar o principal programa Elmo em um jogo de 100 matchmaking. AlphaZero venceu 90 jogos, perdeu oito e empatou 2.
Ok, ok, mas vamos parar um pouco, de onde vem todos esses programas de xadrez que aprendem sozinhos e jogam melhor que o campeão mundial?
Não perca nosso curso Alphazero na nossa academia online de xadrez
História da inteligência artificial em jogos de aprendizagem autônoma
Para responder a essa pergunta, precisamos voltar um pouco na história da inteligência artificial em jogos de aprendizagem autônoma.
Nossa aventura começa com um engenheiro chamado Arthur Samuel, que seria um pioneiro no desenvolvimento da inteligência artificial e, especialmente, na criação do “Aprendizado de Máquina” ou aprendizado automático.
No final de 1948, Samuel leu o famoso artigo de Shannon sobre como escrever um programa para jogar xadrez. Ele então decidiu escrever um que jogava em damas inglesas, que considerava mais fácil de programar; Nada poderia estar mais longe da verdade. Samuel disse: “Achei que seria um trabalho trivial programar um computador para jogar damas em inglês.”

Mas a verdade é que ele teve que fazer tudo do zero, já que o artigo escrito por Shannon apenas prototipou a ideia, mas não escreveu nenhum código. Felizmente para as gerações que viriam depois (nós entre elas  Samuel ficou obcecado por ideologia e, após vários anos de trabalho e pesquisa árdua, conseguiu desenvolver o jogo que tanto desejou
Samuel ficou obcecado por ideologia e, após vários anos de trabalho e pesquisa árdua, conseguiu desenvolver o jogo que tanto desejou
Em 1959, publicou seu primeiro artigo sobre aprendizado computacional sob o título: “Alguns Estudos sobre Aprendizado de Máquina Usando o Jogo das Damas”, onde apresentou seu programa usando poda alfa-beta, que ainda é usado hoje por vários programas para jogar xadrez.
Naquela época, Samuel teve a alegria de trabalhar na IBM no computador 701, no qual pôde testar seu programa. Colocou 4 computadores para jogar milhares de partidas de damas entre si, cujos dados dos resultados das partidas estavam se acumulando, permitindo que as máquinas “Aprendessem com a experiência” e, consequentemente, melhorassem seu desempenho, com o que nasceu o “Aprendizado de Máquina” ou aprendizado automático.
 Samuel ficou tão orgulhoso da evolução da “inteligência” de seu jogo que desafiou o campeão estadual de Connecticut, que era o quarto jogador mais forte dos Estados Unidos. O programa de Samuel, claro, derrotou facilmente o ser humano.
Samuel ficou tão orgulhoso da evolução da “inteligência” de seu jogo que desafiou o campeão estadual de Connecticut, que era o quarto jogador mais forte dos Estados Unidos. O programa de Samuel, claro, derrotou facilmente o ser humano.
Mais tarde, outros programas de Inteligência Artificial viriam ao Try Chess, como Neuro Chess Sebastian Trun, Morph de Robert Arlen Levinson e SAL de Michael Gherrity, entre outros.
NeuroChess
NeuroChess é um programa de xadrez que aprende com uma combinação de autoaprendizagem e observação especializada em jogos. Seu algoritmo de busca é  emprestado do gnuchess, mas seu avaliador é uma rede neural. Na verdade, ele usa duas redes neurais, uma chamada V, que é a função de avaliação, e outra chamada M, que é uma rede neural do bom jogo de xadrez, ou seja, treinada com uma grande amostra de jogos de grandes mestres, o que ajuda a prever os melhores lances. Como o leitor pode ver, Neurochess não é 100% autossuficiente, pois usa a combinação de aprendizado com o reforço de dados dos grandes mestres, o que teve que ser feito porque, quando o jogo era tentado aprender, era muito fraco nas aberturas e expôs a dama cedo.
emprestado do gnuchess, mas seu avaliador é uma rede neural. Na verdade, ele usa duas redes neurais, uma chamada V, que é a função de avaliação, e outra chamada M, que é uma rede neural do bom jogo de xadrez, ou seja, treinada com uma grande amostra de jogos de grandes mestres, o que ajuda a prever os melhores lances. Como o leitor pode ver, Neurochess não é 100% autossuficiente, pois usa a combinação de aprendizado com o reforço de dados dos grandes mestres, o que teve que ser feito porque, quando o jogo era tentado aprender, era muito fraco nas aberturas e expôs a dama cedo.
Morphling

Morph é um sistema adaptativo de xadrez orientado a padrões que aprende a jogar xadrez apenas com sua experiência.
Morph representa o conhecimento do xadrez como padrões ponderados, que são chamados de “pws” para “pares de padrões e pesos”. Padrões são gráficos das relações de ataque e defesa entre as peças no tabuleiro e os vetores da diferença relativa de material entre os jogadores.
Quando o Morph analisa uma posição de xadrez, ele calcula quais padrões correspondem à posição e usa uma fórmula global para combinar os pesos dos padrões correspondentes em uma avaliação. Morph faz o movimento com a melhor avaliação.
Morph utiliza uma grande variedade de métodos de aprendizado para aprender padrões e seus pesos.
SAL

SAL é um sistema geral de aprendizado de jogos escrito por Michael Gherrity, cientista da computação e pesquisador de IA na Universidade da Califórnia, San Diego, que o escreveu para sua tese de doutorado em 1993
Diferente do Morph, o SAL não só joga xadrez, mas também pode aprender e jogar qualquer jogo de tabuleiro entre dois oponentes, desde que o jogo possa ser jogado em um tabuleiro retangular e utilize tipos fixos de peças.
A função de avaliação do SAL é uma rede neural de retropropagação (ela na verdade usa avaliadores separados para os dois lados do jogo). As entradas de rede são recursos que representam a posição do prato, o número de peças de cada tipo no prato, o tipo de peça que você acabou de mover, o tipo de peça que acabou de capturar, e várias características ad hoc relacionadas a peças, quadrados sob ataque e ameaças para vencer o jogo.
SAL foi testado nos jogos do jogo do velho, nos quais dominou após 2000 jogos, conectando quatro com 100.000 partidas e xadrez com 4.200, embora tenha sido suspenso, mas sabe-se que ele estava melhorando com a experiência adquirida em milhares de partidas.
O importante sobre o SAL é que, assim como o ALphaZero, ele aprende sozinho com experiência e pode jogar outros jogos de tabuleiro além do xadrez.
Bem, contagem histórica suficiente por enquanto, vamos focar agora no AlphaZero
Como funciona o AlphaZero?
Para fornecer uma resposta que nos aproxime o máximo possível, vamos bordá-la a partir de duas fontes
Uma será a informação compartilhada sobre o AlphaZero pela equipe do DeepMind e a outra será das informações compartilhadas pela mesma equipe, mas sobre o Giraffe, cujo código está disponível ao público, o que nos permitirá uma abordagem mais precisa de como o AlphaZero funciona
Embora o código-fonte deste último ainda não tenha sido divulgado; no entanto, a equipe que o desenvolveu tornou conhecidos os aspectos mais relevantes do programa e também devemos lembrar que o AlphaZero é a versão aprimorada do AlphaGo cujo código está disponível e cuja operação é conhecida em maior detalhe.
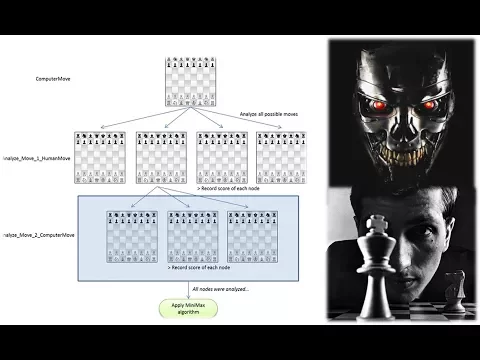
A imagem a seguir mostra a arquitetura do AlphaGoZero (por favor, devido ao seu tamanho, sugerimos que você baixe e dê zoom nas diferentes partes para entender melhor)
Como pode ser visto na imagem, o AlphagoZero é composto por três estágios que rodam em paralelo:
 Jogo Próprio: nesse eatpa é criado um conjunto de treino; no caso do AlphaZero, sabe-se que ele jogou 4 partidas contra si mesmo em 3 dias.
Jogo Próprio: nesse eatpa é criado um conjunto de treino; no caso do AlphaZero, sabe-se que ele jogou 4 partidas contra si mesmo em 3 dias.
A cada movimento, informações conhecidas como “status do jogo” são armazenadas, permitindo que o programa analise probabilidades de busca por meio de seu MCTS (Busca Monte Carlo)
 Rede de Requalificação:
Rede de Requalificação:
Essa rede usa os estados do jogo mencionados como dados de entrada e realiza um ciclo de retreinamento com um lote das melhores posições extraídas dos últimos 500.000 jogos.
Otimização dos Pesos de Rede
Essa etapa também contém uma Função de Perda, que compara as previsões da rede neural com as probabilidades de busca para escolher as jogadas que considera vencedoras.
Após cada 1.000 loops de treinamento, a rede se autoavalia para prever melhor o jogo do adversário.
 Avaliação de Rede: Como a imagem mostra claramente, essa fase faz jogos internos com suas redes sobre as variações apresentadas no tabuleiro para deduzir os melhores movimentos.
Avaliação de Rede: Como a imagem mostra claramente, essa fase faz jogos internos com suas redes sobre as variações apresentadas no tabuleiro para deduzir os melhores movimentos.
Teste para ver se a nova rede é mais forte.
Jogue 400 partidas entre a rede neural mais recente e a melhor rede neural atual
Ambas as redes de jogadores usam MCTS (Busca de Monte Carlo) para selecionar seus movimentos, com suas respectivas redes neurais para avaliar os nós folha. O último jogador deve vencer 55% dos jogos para ser declarado o novo melhor jogador entre essas duas redes.
Pesquise Monte Carlo, para não entediar demais os leitores, não vou entrar em detalhes técnicos sobre isso. Basta dizer por enquanto que é um algoritmo heurístico que analisa os movimentos mais promissores. Busca simular uma árvore de jogo como no algoritmo Min-Max, realizando cálculos e iterações, e com esses resultados conclui qual movimento tem mais chance de vencer o jogo.
Sabe-se então que o algoritmo AlphaZero funciona em um único computador equipado com quatro Unidades de Processamento Tensorial (TPUs), circuitos integrados desenvolvidos especificamente para aprendizado de máquina. Na verdade, o Google lançou sua biblioteca “TensorFlow”, que tem sido sua principal biblioteca para o trabalho de Aprendizado de Máquina e redes neurais em Inteligência Artificial (em breve farei um vídeo onde mostrarei como aproveitar essa biblioteca por meio de um programa que usa IA).
Em 2 de novembro de 2017, foi lançada a versão estável 1.4 do TensorFlow, você pode saber mais em tensorflow.org
GIRAFA
Mathew Lai, criador de Girafa e membro da equipe DeepMind

Por fim, quero falar um pouco sobre Girafa, a Girafa, para meu precursor do agora famoso Alpha, Girafa, foi desenvolvido por Mathew Lai, membro do DeepMind, como sua tese de mestrado sobre inteligência artificial no desenvolvimento de um programa de xadrez que aprende sozinho, sem intervenção humana, o que foi alcançado, porque a joia, após ser acesa, atingiu o nível de um mestre de xadrez após 72 horas de jogo sem interrupções contra si mesmo.
Giraffe usa Aprendizado de Máquina, Aprendizado Profundo e “Aprendizado por Reforço” assim como o AlphaZero.
A boa notícia, e é aqui que vem o presente de Natal para nossos leitores, que o código-fonte do Girafa foi liberado e pode ser baixado tanto da internet quanto do motor UCI, para que você possa instalá-lo livremente no seu Fritz. Pessoalmente, a sensação de jogar contra essa engine é que você sente que está jogando contra uma pessoa e não contra uma máquina, e é maravilhoso sentir que você está jogando contra uma engine que não usa força bruta, mas inteligência artificial.
No final do artigo, você encontrará os links para baixá-lo.
O GÊNIO POR TRÁS DO GÊNIO DO ALPHAZERO
Demis Hassabis, o gênio que fundou a DeepMind

Não posso encerrar este artigo sem mencionar o cérebro por trás de tudo isso, que é Demis Hassabis, CEO da DeepMind Technologies; que era considerado um prodígio infantil do xadrez, aos 13 anos já possuía um ELO de mais de 2300 pessoas.
Em 1999, aos 23 anos, ele venceu a Mental Sports Olympiad, uma competição internacional multidisciplinar anual para jogos de habilidade mental. Ele venceu o jogo um recorde de cinco vezes antes de se aposentar das competições em 2003.
Demis dedicou-se totalmente à pesquisa em inteligência artificial, fundando a DeepMind, que foi comprada em 2014 pelo Google por £400 milhões.
Conclusões
Se o leitor me permitir, quero tirar algumas conclusões sobre Alphazero e IA no xadrez, que são duas das minhas paixões.
Algumas pessoas estão prejudicando as conquistas do Alphazero ao mencionar que ele jogou contra uma versão ruim do Stokfisch, etc. Entendo suas observações, também tenho um carinho especial pelo StockFisch, mas a verdade é que módulos como Stokfisch, Ribka, Houdini, etc. são baseados em força bruta apoiados por uma evolução interessante de algoritmos, mas o AlphaGo é baseado em Inteligência Artificial e seus algoritmos são muito mais eficientes, “eles estão vivos”, aprendem sozinhos.
A inteligência artificial não nasceu ontem, desde os anos 60 ela continuou a evoluir e ganhou força no mundo atual graças aos avanços em computação, hardware e massificação das TIC (Tecnologias da Informação e Comunicação), então digo isso com muito respeito. Os módulos que conhecemos não têm muito a ver com esses monstros da IA e, no futuro, se continuarem se enfrentando, veremos como eles caem irremediavelmente diante do ritmo esmagador da IA. Mas isso não deve nos desagradar, pelo contrário, deve nos motivar, porque amantes do xadrez, de alguma forma, são os beneficiários e já somos abençoados por poder contemplar essas maravilhas. Imagine o que nossos filhos e as futuras gerações verão.
Agora, mencionei que isso pode nos beneficiar e você pode se perguntar como, porque a resposta tem exatamente a ver com o que cientistas da computação como Tom Mitchell, da Universidade Carnegie Mellon, dizem
“… Um novo livro começa, onde os computadores ensinam os humanos a brincar para ir melhor do que antes.”[1]
Na Ásia, por exemplo, estudiosos de Go dizem que usam para analisar novas estratégias que o jogo descobriu e que alguns dos melhores jogadores estavam apenas pesquisando.
Semelhante ao relatório que eles apresentaram sobre as aberturas descobertas pela AlphaZero no xadrez, que coincidem com aquelas que predominam na competição moderna, além de outras estratégias que a AlphaZero mostrou.
Quanto à questão de se os seres humanos um dia vão jogar como máquinas, a resposta é um retumbante “NÃO”, porque nosso sistema de aprendizado é muito mais lento, apesar de termos muito mais conexões neurais do que o Google, mas à questão de saber se podemos melhorar nosso jogo graças a IAs como a ALphaGo, a resposta é “Sim” e é aqui que paro, desde alguns anos atrás, venho trabalhando em um projeto de pesquisa que busca aproveitar algumas metodologias de IA que podem ser aplicadas na aprendizagem humana para torná-la mais eficiente, não só no xadrez, mas também no aprendizado de várias tarefas, como dominar uma língua, por exemplo, mas bem, essa é outra história.
LINKS DE INTERESSE:
Código-fonte SAL, escrito em C:http://www.gherrity.org/sal6.tar.gz
Código-fonte de Girafa, escrito em C++: https://github.com/ianfab/Giraffe
Motor Girafa UCI: https://drive.google.com/file/d/0BwDWupDvQ-QWQjAwMU9sNm0wd0U/view
Artigo sobre girafas, https://arxiv.org/pdf/1509.01549.pdf
Site DeepMind: https://deepmind.com/
AlphaZero e papel de xadrez: https://arxiv.org/pdf/1712.01815.pdf
Google Library para experimentar com IA: https://www.tensorflow.org/
*P.S., se você quiser saber um pouco mais sobre esse assunto, convido você a assistir ao meu vídeo sobre a evolução da inteligência artificial no xadrez: https://youtu.be/bqNZd6BC1WI